Part VII. Reference Implementation¶
Up to this point, we assembled the same system layer by layer:
- architecture and trust boundaries;
- memory;
- execution layer;
- observability;
- operating model.
Now it is time to turn that into a more coherent reference implementation. Not an "ideal framework for every use case", but a practical blueprint of the same support agent and surrounding platform that you can use as a starting point and evolve further.
Short path through this part
If you want a fast pass, read it this way:
- Chapter 16: see how the same support agent becomes one runtime instead of a pile of local handlers;
- Chapter 17: see how that runtime gets an explicit policy layer and capability catalog;
- Chapter 18: check whether that skeleton is ready for a limited rollout and further growth.
Together, this shows that the reference implementation is not for demo value. It is for fixing the production system in code.
Read as one argument, this part moves through three promises: Chapter 16 gives the runtime a runnable structure, Chapter 17 gives that structure a governed contract core, and Chapter 18 asks whether the same system can withstand real go/no-go pressure.
Part VII canonical case routes
In the reference implementation, the three canonical cases should appear as different runtime paths. Support triage checks the run loop, capability catalog, approval pause/resume, and rollout checklist for ticket writes. Internal knowledge assistant checks the memory/retrieval service, read capability policy, source attribution, and tenant isolation. Incident coordination checks escalation capability, notification side effects, incident state handoff, and rollout readiness evidence.
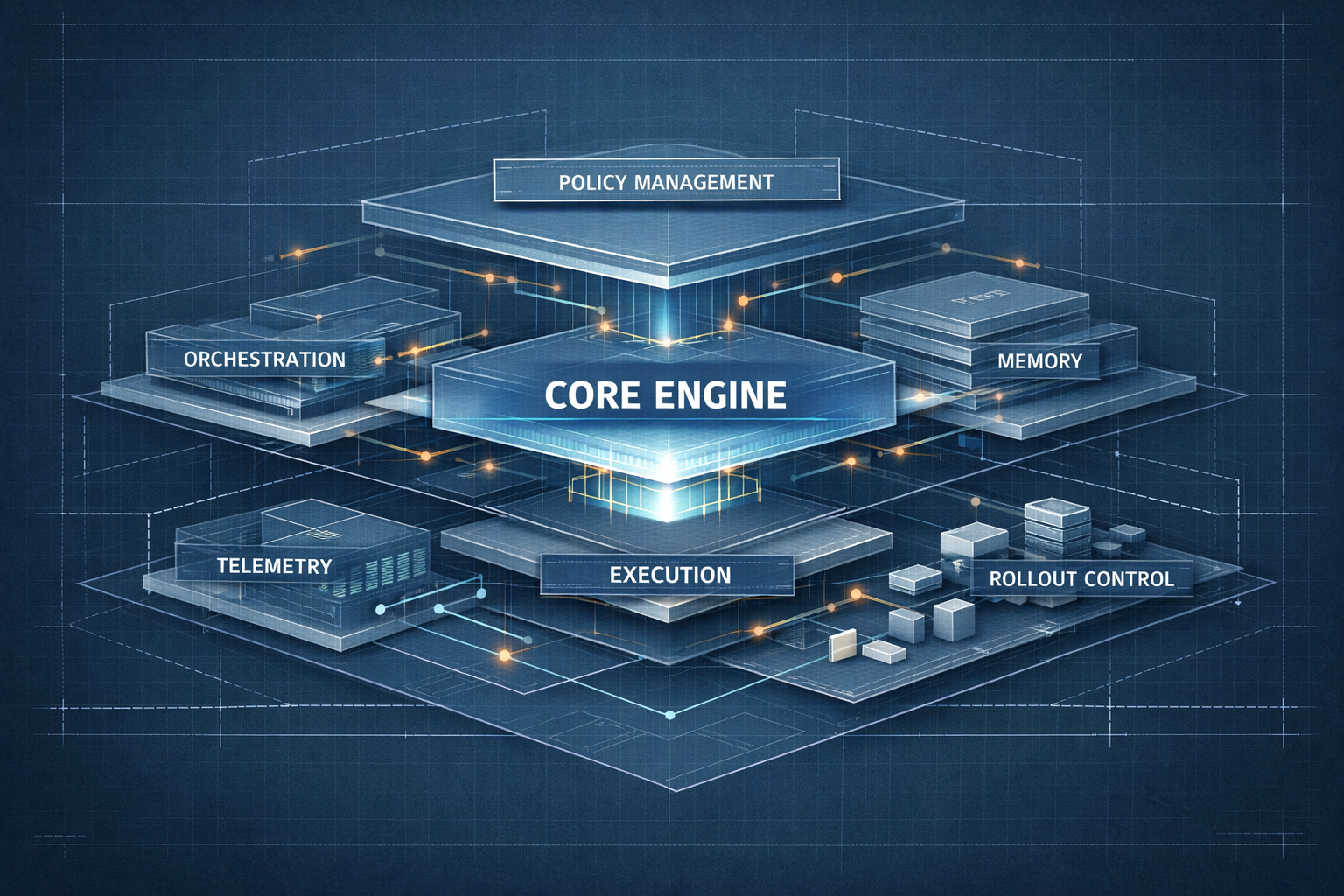
In this part, I gradually assemble a minimally mature platform:
- a baseline runtime;
- security and policy hooks;
- a capability catalog;
- telemetry wiring;
- a rollout checklist.
What This Part Solves¶
- it gathers architecture, memory, execution, and observability into one runtime skeleton;
- it fixes the contract core through the policy layer and capability catalog;
- it treats approval and governed capability access as explicit runtime behavior rather than side process;
- it brings that skeleton up to first-rollout readiness;
- it turns the operating model from Part VI into an executable runtime and rollout shape.
This part is where the book turns abstract layers into a runnable system. It is the bridge between the earlier architectural argument and the later lifecycle argument.
In This Part¶
- Chapter 16. Baseline Runtime Blueprint This chapter continues the same support case at the code layer: where the run loop should live, how to separate policy, memory, and execution, and how not to spread logic across local handlers.
- Chapter 17. Policy Layer and Capability Catalog This chapter lifts the same skeleton into the contract layer: which capabilities are allowed at all, where approval is required, how pause/resume approval paths should work, and how not to hardcode risk logic into orchestration.
- Chapter 18. Production Rollout Checklist This chapter closes the same story through the first limited rollout: whether the support agent is ready for real deployment, whether approval/policy signals are observable, and what must already be visible before scaling.
Where It Leads Next¶
After this part, it becomes clear how architecture, safety, memory, execution, observability, and approval control form one operational skeleton. But production discipline does not stop there.
Once the same agent survives its first rollout, the next questions separate cleanly into new roles:
- change management decides which changes are release-bearing;
- assurance decides how to respond when drift and findings appear;
- provenance and approved artifacts preserve the evidence backbone of what was actually deployed;
- observability expands from runtime wiring into estate-level evidence substrate;
- registry and governance decide who is accountable across the estate;
- retirement closes the lifecycle when the system should no longer remain active.
That is why the next natural step after the reference implementation is Part VIII. Agent System Lifecycle, where the same system is re-read through lifecycle frame, release judgment, response, evidence backbone, lifecycle closure, adversarial pressure, judgment, evidence substrate, and estate accountability.